Quando não existe key, ou quando ela é escolhida sem critério, o Kafka continua funcionando.
Mas a arquitetura começa a cobrar a conta.
No post anterior, falamos sobre hot partition e como a distribuição ruim de carga destrói o paralelismo real. Antes disso acontecer, quase sempre existe uma decisão mal resolvida: a escolha da key.
Conceito: o que a key realmente define
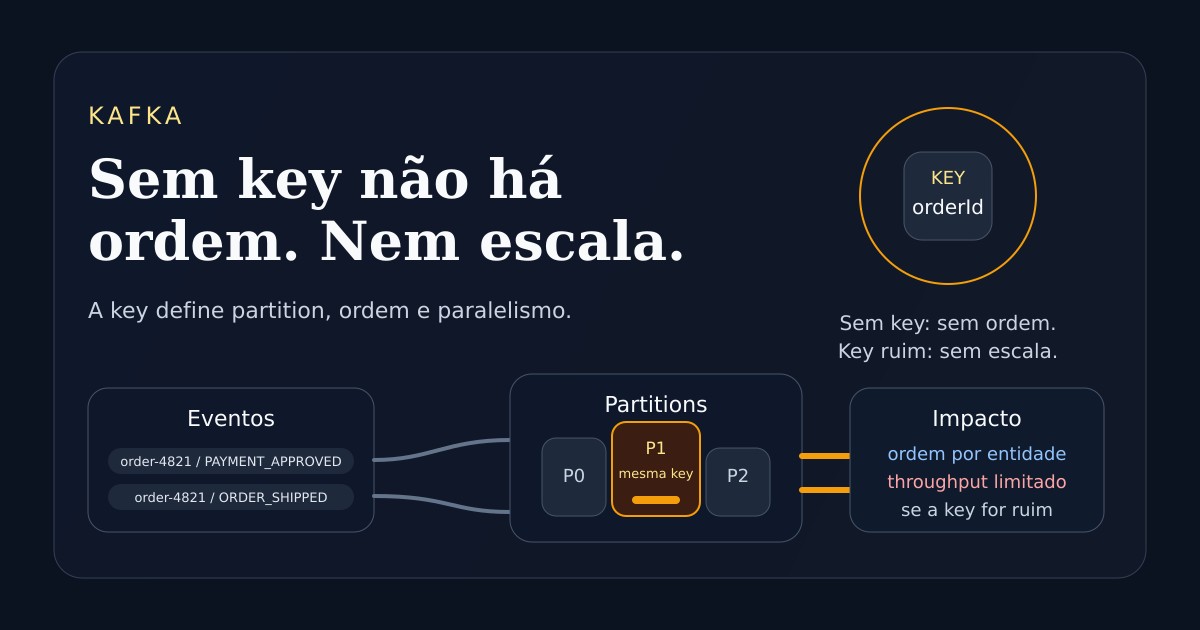
No Kafka, a key não é apenas um metadado da mensagem.
Ela influencia diretamente em qual partition o evento será gravado.
E isso afeta três coisas ao mesmo tempo:
- a ordem dos eventos
- a distribuição de carga
- o limite máximo de paralelismo no consumo
Se dois eventos da mesma entidade usam a mesma key, eles tendem a cair na mesma partition.
É isso que preserva a ordem daquela entidade.
Mas existe um custo estrutural:
Tudo que cai na mesma partition será processado em sequência por um único consumer ativo daquele group.
Ou seja:
- a key define onde o evento entra
- a partition define onde a ordem existe
- a quantidade e a distribuição entre partitions definem o quanto o consumo consegue escalar
Sem essa leitura, a equipe discute lag, throughput e escalabilidade como se fossem problemas separados.
Não são.
O erro mais comum: tratar key como detalhe
Muita decisão de particionamento nasce assim:
- "vamos sem key por enquanto"
- "coloca
tipoEvento, depois a gente vê" - "usa qualquer campo que já exista no payload"
Em ambiente real de produção, isso costuma virar problema em pouco tempo.
Sem key, eventos da mesma entidade podem cair em partitions diferentes.
Em stacks como Spring Kafka, isso também costuma gerar confusão.
Se você não informa a key, o framework não cria automaticamente uma key de negócio para você.
A mensagem segue sem key, e a escolha da partition fica com a estratégia padrão do producer.
Hoje, essa estratégia costuma ser a sticky partition: o producer envia para uma partition por um tempo para otimizar batching e depois troca.
Isso pode até ajudar throughput na produção.
Mas não preserva ordem por entidade nem substitui uma decisão consciente de particionamento.
Resultado:
- a ordem por entidade deixa de existir
- o processamento fica mais difícil de raciocinar
- bugs intermitentes começam a parecer "efeito colateral normal"
Com uma key ruim, o efeito muda, mas continua custando caro.
Se a cardinalidade for baixa, como status, tipoEvento ou canal, a distribuição fica limitada desde o início.
Se a key fizer sentido de negócio, mas poucos valores concentrarem volume demais, você cai no cenário clássico de hot partition.
Cenário real
Imagine um tópico de eventos financeiros que alimenta o cálculo de saldo consolidado do cliente.
O producer publica sem key.
No papel, parece bom: o Kafka distribui melhor a carga entre as partitions.
Agora pense em uma conta com saldo inicial de R$ 1.000.
Em poucos segundos, acontecem estes eventos:
COMPRA_AUTORIZADAdeR$ 200ESTORNO_PROCESSADOdeR$ 200SAQUE_CONFIRMADOdeR$ 900COMPRA_AUTORIZADAdeR$ 100
Se a aplicação processa na ordem correta:
- saldo inicial:
R$ 1.000 - compra: saldo vai para
R$ 800 - estorno: saldo volta para
R$ 1.000 - saque: saldo final fica em
R$ 100 - nova compra de
R$ 100: transação aprovada e saldo vai paraR$ 0
Agora o problema.
Sem key, esses eventos podem cair em partitions diferentes e chegar fora de ordem ao consumidor.
Se a aplicação processa na ordem incorreta:
- saldo inicial:
R$ 1.000 - compra: saldo vai para
R$ 800 - saque: saldo vai para
R$ -100 - o sistema pode disparar bloqueio, alerta ou recusa indevida
- a nova compra de
R$ 100pode ser recusada por falta de saldo - só depois o estorno entra e o saldo volta para
R$ 100
Só que o erro já apareceu para o cliente ou para outro sistema dependente.
Para o cliente, isso aparece como inconsistência real:
- saldo exibido diferente do esperado
- limite disponível calculado errado
- extrato com eventos fora de sequência lógica
Agora imagine o outro extremo.
O time decide usar tipoEvento como key para "organizar melhor".
Só existem poucos valores possíveis.
Resultado:
- algumas partitions concentram grande parte do tráfego
- outras partitions ficam subutilizadas
- parte dos consumers fica ociosa
- o lag sobe exatamente onde a carga se concentrou
O cluster pode continuar saudável.
Mesmo assim, o throughput total fica travado pela pior distribuição possível.
O impacto real em produção
Quando a key é ausente ou inadequada, o efeito costuma aparecer em quatro sintomas:
-
Perda de ordenação por entidade: Eventos relacionados ao mesmo cliente, pedido ou conta deixam de ter sequência garantida.
-
Hot partitions: Poucas partitions concentram trabalho demais e viram gargalo.
-
Consumers ociosos: O grupo tem capacidade disponível, mas não existe trabalho bem distribuído para aproveitar essa capacidade.
-
Throughput limitado com cluster saudável: Brokers estão bem, mas o consumo não escala porque o particionamento virou o teto real do sistema.
Esse é o ponto que costuma confundir bastante.
O time olha CPU, disco, rede, número de pods.
Só que o limite já foi imposto antes, na hora de decidir como os eventos seriam distribuídos.
Como pensar uma boa key
A pergunta correta não é "qual campo eu posso usar?".
É esta:
"Qual entidade precisa de ordem e como isso afeta minha capacidade de distribuir carga?"
Na maioria dos cenários, boas candidatas são chaves ligadas à entidade de negócio:
customerIdorderIdaccountIdsellerId
Mas isso, sozinho, não encerra a análise.
Também é preciso validar:
- essa entidade realmente precisa de ordem?
- a cardinalidade é suficiente?
- existem poucos IDs concentrando volume acima da média?
- essa estratégia continua saudável quando o sistema crescer?
Uma key boa não é só semanticamente bonita.
Ela precisa equilibrar duas coisas:
- consistência de processamento
- distribuição real de carga
Arquitetura aqui é tradeoff.
Preservar ordem demais pode custar throughput demais.
Regra de ouro
No Kafka, particionamento não é detalhe de implementação.
É decisão de arquitetura.
Sem key, você perde previsibilidade de ordem.
Com key ruim, você perde distribuição.
Nos dois casos, quem paga a conta é o consumo.
Seu time hoje escolhe key com base na regra de negócio e no padrão real de tráfego, ou só descobre o impacto quando o lag aparece?