Tudo parece normal.
A aplicação está consumindo mensagens, os logs mostram atividade, o lag não parece fora de controle e o fluxo segue rodando em produção.
Só que, algum tempo depois, alguém percebe um problema incômodo: certos dados simplesmente não foram persistidos.
A mensagem passou pelo consumer, mas o efeito esperado nunca apareceu no banco, no sistema de destino ou no estado final da operação.
Em muitos casos, a causa não está no broker nem em uma “mensagem perdida” no transporte. O problema está no momento em que o consumer decidiu confirmar avanço de leitura.
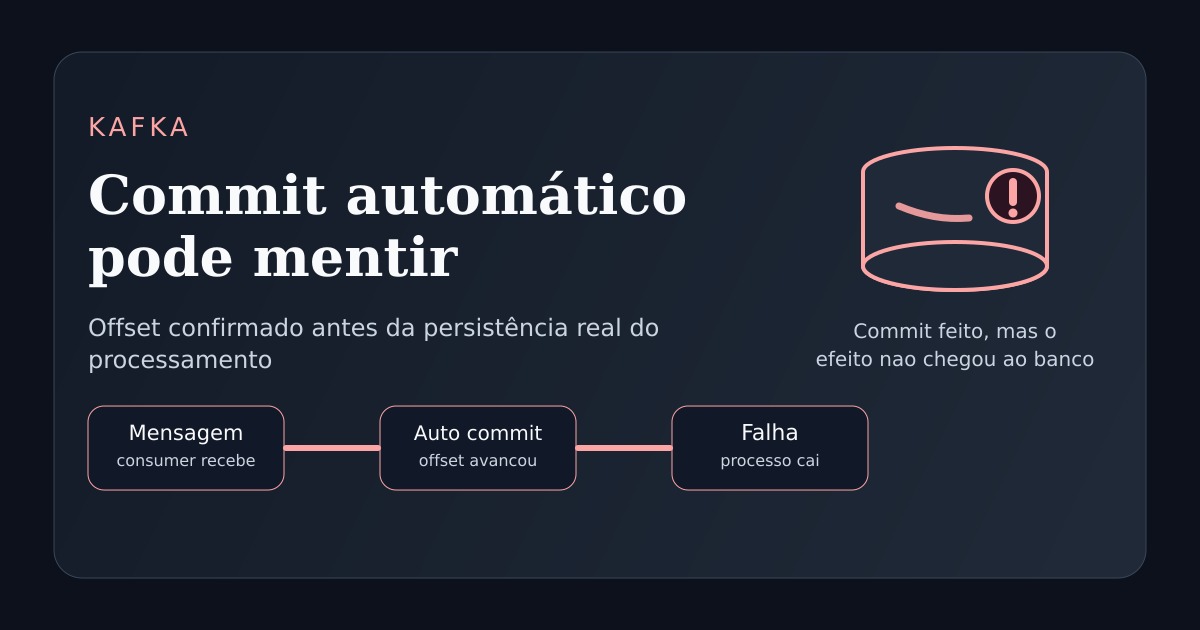
É aqui que o auto commit pode mentir.
O que o commit realmente está confirmando
Em Kafka, cada consumer acompanha sua posição de leitura por meio do offset.
O offset é, na prática, o marcador que indica até onde aquele consumer já avançou em uma partition.
Quando o consumer faz commit, ele registra que determinada posição já pode ser considerada concluída para futuras retomadas.
Esse ponto é importante: fazer commit não significa que a lógica de negócio terminou com sucesso.
Significa apenas que o consumer confirmou para o Kafka qual é o próximo ponto a partir do qual pretende continuar lendo.
Com auto commit, essa confirmação acontece automaticamente em intervalos configurados, sem depender do sucesso real do processamento da mensagem.
Com commit manual, o consumer controla esse momento de forma explícita e pode decidir confirmar o offset só depois que o trabalho crítico foi realmente concluído.
Essa diferença parece pequena no código, mas muda bastante a confiabilidade do consumo.
O cenário que costuma enganar em produção
Imagine um consumer lendo uma mensagem de atualização de pedido.
O registro é recebido normalmente, o código entra na rotina de processamento e o offset acaba sendo commitado automaticamente.
Até aqui, olhando de fora, tudo parece saudável. O consumer leu a mensagem e o grupo avançou.
Mas logo depois acontece a parte crítica: antes de persistir o dado no banco, a aplicação falha.
Pode ser uma exceção não tratada, queda do processo, interrupção da instância ou erro em algum recurso externo.
O efeito prático é o mesmo. O offset já foi confirmado, mas a lógica de negócio não terminou.
Quando a aplicação volta, aquele registro não será lido de novo como se estivesse pendente.
Do ponto de vista do Kafka, o consumer já informou que avançou além daquela mensagem.
É por isso que o auto commit pode criar uma falsa sensação de sucesso: o progresso de leitura foi confirmado, mas o processamento real ficou incompleto.
Em muitos times, o auto commit não fica ativo apenas por conveniência. Ele também costuma ser mantido porque a estratégia de retry e tratamento de falhas já foi desenhada em volta desse comportamento. O problema é que retry, por si só, não corrige o momento errado do commit. Se o offset avançar antes da conclusão real do processamento, a aplicação pode falhar depois e ainda assim deixar para trás uma perda lógica difícil de perceber.
O impacto real desse comportamento
O primeiro impacto é a perda lógica de mensagem.
A mensagem pode até ter sido entregue ao consumer, mas o efeito esperado nunca foi materializado. Na prática, o sistema se comporta como se aquele evento tivesse desaparecido do fluxo de negócio.
O segundo impacto é a inconsistência de dados.
Quando parte do processamento foi concluída e outra parte não, surgem estados quebrados: pedido criado sem atualização de estoque, evento registrado sem persistência final, integração parcial sem reconciliação clara.
O terceiro impacto é a dificuldade de diagnóstico.
Como o offset já avançou, o time muitas vezes não enxerga backlog, não vê retry natural e não encontra erro óbvio olhando apenas para métricas superficiais de consumo.
O problema passa a parecer intermitente, raro ou até “impossível de reproduzir”, quando na verdade o sistema confirmou leitura cedo demais.
Boas práticas para reduzir esse risco
A primeira é considerar commit manual depois do sucesso real do processamento.
Se a mensagem só pode ser considerada concluída após persistência, chamada externa ou atualização de estado, o commit precisa respeitar esse ponto de verdade.
A segunda é garantir idempotência.
Em sistemas distribuídos, reprocessamento não é exceção. Se uma mensagem puder ser executada novamente sem corromper o resultado final, a recuperação de falhas fica muito mais segura.
A terceira é tratar erros explicitamente.
Falha de processamento não deve se misturar com avanço silencioso de offset. É melhor decidir conscientemente entre retry, registro de erro, envio para tratamento posterior ou interrupção controlada do fluxo do que deixar o sistema “seguir em frente” com perda lógica escondida.
Kafka entrega, mas quem garante o processamento é o consumidor
Kafka não garante que a sua lógica de negócio foi executada com sucesso.
Ele garante entrega e coordenação de leitura dentro do modelo proposto pela plataforma.
A confiabilidade do processamento depende de como o consumer confirma offsets, trata falhas e protege operações críticas.
Por isso, auto commit não deve ser encarado como simples conveniência operacional.
Em muitos cenários, ele pode mentir.
A mensagem foi lida, o offset avançou, o gráfico parece saudável e ainda assim o dado não chegou onde precisava chegar.
No fim, o Kafka não confirma processamento. Quem faz essa garantia, ou deixa de fazer, é o consumidor.