Tudo parecia normal.
Um serviço publicava eventos, vários consumidores liam o tópico e cada time seguia evoluindo sua parte do sistema sem grandes incidentes.
Até que alguém fez uma mudança simples: renomeou um campo, removeu um atributo que parecia inútil ou adicionou um novo valor reaproveitando o payload que já existia.
O deploy passou. Nenhum alerta explodiu na hora.
Só depois começaram os sintomas: um consumidor deixou de persistir dados corretamente, outro passou a interpretar o evento de forma errada e um pipeline analítico começou a gerar informação inconsistente.
Esse tipo de falha costuma ser traiçoeiro porque não parece, à primeira vista, um problema de contrato.
Mas muitas vezes é exatamente isso.
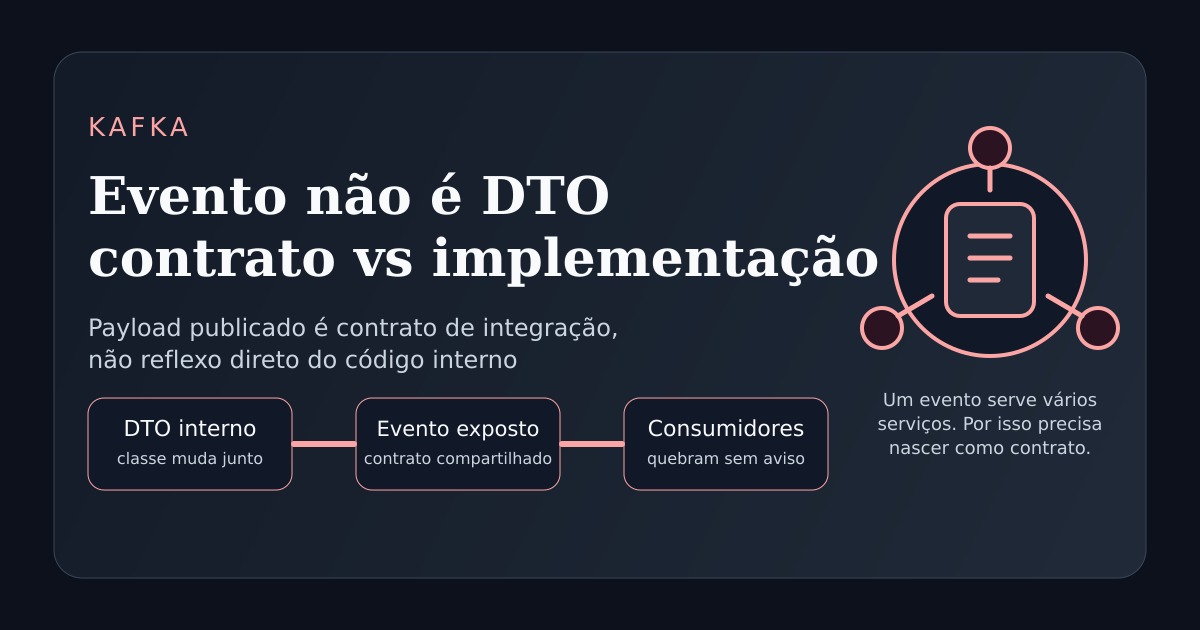
DTO e evento não são a mesma coisa
Um DTO é uma estrutura interna do serviço. Ele existe para organizar dados dentro da aplicação e costuma mudar junto com o código, com a modelagem e com as decisões locais daquele time.
Um evento é outra coisa.
Ele é um contrato de integração entre serviços. Ele precisa representar um fato de negócio que outros consumidores consigam entender e processar com previsibilidade.
Essa diferença é central.
Quando um evento nasce como reflexo direto de uma classe interna, o sistema começa a tratar um detalhe de implementação como se fosse uma interface pública.
E interface pública precisa evoluir com mais cuidado do que uma classe local.
Evento não deveria dizer “esta é a minha estrutura interna atual”.
Evento deveria dizer “este fato de negócio aconteceu”.
O erro comum: publicar o DTO direto no Kafka
Esse erro aparece muito em arquiteturas orientadas a eventos.
O serviço já possui um objeto pronto em memória, então parece natural serializar aquilo e publicar no tópico.
No começo, funciona.
O problema é que esse contrato fica implícito e não documentado. Ele não foi pensado como interface de integração. Ele apenas vazou do serviço produtor para fora.
Quando o time altera um nome de campo, remove um atributo ou reorganiza o payload por conveniência interna, outros serviços podem ser impactados sem aviso real.
Esse problema fica ainda mais claro quando o fluxo publica mudanças capturadas direto da base. Nesse cenário, o evento deixa de representar um fato de negócio e passa a expor o próprio domínio do banco, com nomes de colunas, estruturas internas e decisões locais de persistência vazando para fora do serviço.
E como vários consumidores podem ler o mesmo tópico, o efeito não é uniforme. Um quebra imediatamente. Outro continua rodando, mas com comportamento incorreto. Outro só falha horas depois, quando usa aquele dado em uma regra mais específica.
Isso aumenta muito o tempo de diagnóstico.
O impacto real em produção
O primeiro impacto é a quebra silenciosa de consumidores.
Nem sempre o processo cai. Às vezes ele apenas passa a interpretar o evento de maneira errada, ignora um dado importante ou grava informação inconsistente.
O segundo é o alto acoplamento entre serviços.
Uma mudança local, que deveria ser interna ao produtor, passa a exigir cuidado de integração com vários times e pipelines diferentes.
O terceiro é o risco de deploy.
Alterações pequenas no código viram mudanças perigosas porque o payload publicado deixou de ser contrato e virou espelho da implementação atual.
O quarto é a instabilidade em pipelines de dados e o custo operacional do diagnóstico.
Quando o problema aparece depois, em consumidores diferentes e com sintomas difusos, descobrir a causa fica caro e lento.
Boas práticas para evoluir sem quebrar consumo
Eventos devem representar fatos de negócio, como invoice.created, payment.confirmed ou order.cancelled.
Isso ajuda a pensar no payload como contrato explícito, não como classe interna serializada.
Também vale versionar eventos quando a evolução exigir mudança incompatível, por exemplo com sufixos como .v1.
Outro ponto importante é desacoplar o modelo interno do payload publicado.
O serviço pode ter seus próprios DTOs, entidades e objetos auxiliares internamente, mas o evento precisa ser montado como uma interface pensada para integração.
E esse contrato já deve nascer com preocupação de evolução de schema: campos opcionais, compatibilidade e mudança gradual fazem parte do desenho, não da correção de emergência.
O ponto que separa um sistema saudável de um frágil
Kafka distribui eventos entre serviços, mas não corrige um contrato ruim.
Se o seu evento muda junto com o seu código interno, ele não está funcionando como contrato de integração.
Está funcionando como vazamento de implementação.
Se seu evento muda junto com seu código, você não tem um evento. Você tem vazamento de implementação.