Rollback é uma palavra confortável.
Ela dá a sensação de que, se algo der errado, o sistema simplesmente volta ao estado anterior.
No banco de dados, dentro de uma transação local, essa sensação faz sentido.
Você abre uma transação, altera tabelas, valida condições e, se algo falhar antes do commit, desfaz tudo.
Nada foi confirmado.
Nada vazou para fora.
O problema começa quando a mesma expectativa é levada para sistemas distribuídos.
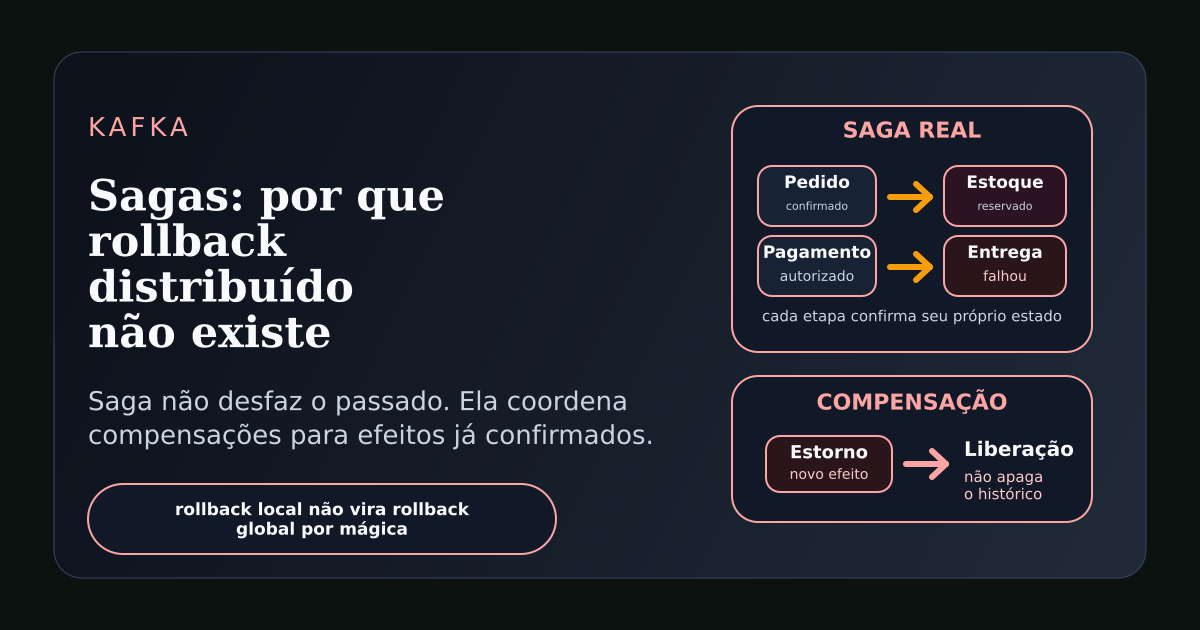
Um pedido foi criado em um serviço.
O estoque foi reservado em outro.
O pagamento foi autorizado em um terceiro.
Uma mensagem foi publicada no Kafka.
Um e-mail foi enviado.
Uma chamada externa foi aceita por um gateway.
Depois disso, alguém pergunta:
"se a última etapa falhar, como damos rollback em tudo?"
A resposta curta é: não damos.
Não no sentido tradicional.
Em sistemas distribuídos, rollback global quase sempre é uma ficção.
O que existe é compensação.
E compensação não é voltar no tempo.
É executar uma nova ação de negócio para lidar com algo que já aconteceu.
Rollback local não vira rollback distribuído
Dentro de um único banco, a transação tem controle sobre os recursos envolvidos.
Ela sabe quais alterações ainda não foram confirmadas.
Ela consegue descartar essas alterações antes que outras partes do sistema dependam delas.
Esse modelo funciona porque existe uma fronteira clara:
- um banco;
- uma transação;
- um mecanismo de commit;
- um coordenador com controle real sobre o que ainda está pendente.
Em um fluxo distribuído, essa fronteira desaparece.
Cada serviço tem seu próprio banco, sua própria transação local e seu próprio momento de confirmação.
Quando o serviço de estoque confirma a reserva, aquilo já virou fato para ele.
Quando o serviço de pagamento autoriza uma cobrança, aquilo já virou fato para o gateway.
Quando um evento é publicado e consumido, outros efeitos podem ter começado.
Não existe um botão universal capaz de entrar em todos esses lugares e apagar o que aconteceu como se nada tivesse existido.
Mesmo que uma tecnologia prometa transação distribuída, o custo, o acoplamento e os limites práticos costumam tornar esse caminho inadequado para a maioria dos fluxos modernos.
Em sistemas orientados a eventos, a pergunta muda.
Não é "como desfazer tudo?".
É "o que o domínio precisa fazer quando uma etapa já confirmada precisa ser compensada?".
Saga é coordenação de efeitos, não mágica transacional
Uma saga é um padrão para coordenar uma sequência de operações distribuídas.
Cada etapa executa uma transação local.
Depois de confirmar sua parte, ela publica um evento ou retorna um resultado para que o processo avance.
Se uma etapa falha, o sistema executa ações compensatórias para etapas que já foram concluídas.
Um checkout simplificado poderia ser:
- criar pedido;
- reservar estoque;
- autorizar pagamento;
- agendar entrega;
- confirmar pedido.
Se o agendamento de entrega falhar depois do pagamento autorizado, não existe rollback do pagamento como se ele nunca tivesse acontecido.
Existe uma nova ação: cancelar ou estornar a autorização.
Se o pagamento falhar depois do estoque reservado, não existe rollback invisível da reserva.
Existe uma nova ação: liberar o estoque.
Essas ações precisam ser modeladas.
Elas têm regra de negócio.
Elas podem falhar.
Elas podem ser assíncronas.
Elas podem depender de prazo, política comercial, integração externa e estado atual do processo.
Por isso, saga não é um detalhe de infraestrutura.
Saga é desenho de processo.
Compensação não é o inverso perfeito da ação original
Um erro comum é imaginar compensação como uma função inversa simples:
reservarEstoque() -> liberarEstoque()
capturarPagamento() -> estornarPagamento()
enviarEmail() -> cancelarEmail()
Na prática, raramente é tão limpo.
Liberar estoque pode ser simples se a reserva ainda estiver ativa.
Mas e se a reserva já expirou?
E se o estoque foi realocado?
E se parte dos itens foi separada fisicamente?
Estornar pagamento também não é apenas "desfazer pagamento".
Pode haver autorização, captura, estorno parcial, prazo de liquidação, tarifa, antifraude, contestação e regras do provedor.
Enviar e-mail é ainda mais evidente.
Depois que a mensagem saiu, não existe rollback.
Você pode enviar outro e-mail corrigindo a informação.
Mas o primeiro já aconteceu.
O mundo externo viu.
Esse é o ponto que torna sistemas distribuídos diferentes de transações locais.
Depois que um efeito escapa da fronteira de um serviço, compensar significa produzir outro efeito.
Não apagar o anterior.
Kafka ajuda no registro e na coordenação, mas não desfaz efeitos
Kafka combina bem com sagas porque ele ajuda a distribuir fatos e preservar histórico.
Um serviço pode publicar OrderCreated.
Outro pode consumir e publicar InventoryReserved.
Outro pode publicar PaymentAuthorized.
Um coordenador pode acompanhar esses eventos e decidir o próximo passo.
O log ajuda a entender o que aconteceu.
Ajuda a reprocessar.
Ajuda a reconstruir estado.
Ajuda a alimentar observabilidade.
Mas Kafka não transforma eventos publicados em efeitos reversíveis.
Se um consumer leu PaymentAuthorized e disparou outra ação, apagar ou ignorar o evento depois não apaga a consequência.
Se um evento foi entregue mais de uma vez, a saga precisa lidar com idempotência.
Se uma compensação falhar, Kafka não resolve a regra automaticamente.
Ele pode carregar o comando de compensação.
Ele pode guardar o fato de que a compensação foi solicitada.
Ele pode permitir retry e investigação.
Mas a decisão de negócio continua sendo sua.
Esse ponto conversa com o post sobre Kafka garantir entrega, mas não processamento: o broker entrega mensagens dentro do modelo dele, mas o efeito correto no domínio depende do consumidor.
Coreografia pode esconder a saga
Em uma saga coreografada, cada serviço reage a eventos e publica novos eventos.
Não existe um coordenador central explícito.
O fluxo parece natural:
- pedido criado;
- estoque reservado;
- pagamento autorizado;
- entrega agendada;
- pedido confirmado.
Quando tudo dá certo, o desenho parece elegante.
O problema aparece quando algo falha.
Quem manda liberar o estoque?
Quem solicita estorno?
Quem marca o pedido como compensando?
Quem decide que um retry já não faz mais sentido?
Quem avisa o cliente?
Quem sabe que a saga terminou em falha compensada, e não apenas em atraso?
Se a resposta estiver espalhada em vários consumers, a saga existe do mesmo jeito.
Ela só está implícita.
E saga implícita costuma ser difícil de operar.
Esse ponto é uma continuação direta do post sobre coreografia e orquestração: todo processo distribuído tem coordenação. A diferença é se ela está visível ou escondida.
Orquestração torna o estado do processo mais explícito
Em uma saga orquestrada, existe um componente responsável por conduzir o processo.
Ele pode enviar comandos, aguardar eventos, registrar estado, controlar timeout e disparar compensações.
O fluxo poderia ser:
CheckoutSaga
-> solicita reserva de estoque
<- estoque reservado
-> solicita autorização de pagamento
<- pagamento autorizado
-> solicita agendamento de entrega
<- entrega falhou
-> solicita cancelamento do pagamento
-> solicita liberação do estoque
-> marca pedido como falha compensada
Esse componente não precisa concentrar toda regra interna dos serviços.
Estoque continua dono da regra de reserva.
Pagamento continua dono da regra de autorização e estorno.
Entrega continua dona da regra logística.
Mas o processo ganha um lugar para responder perguntas operacionais:
- em que etapa a saga está?
- qual foi a última decisão?
- qual compensação está pendente?
- qual tentativa falhou?
- qual timeout expirou?
- o cliente já pode ser avisado?
Isso não torna orquestração sempre melhor.
Para fluxos simples, coreografia pode ser suficiente.
Mas quando a falha exige compensação coordenada, estado explícito costuma valer mais do que a aparência de desacoplamento.
Idempotência é parte da saga
Saga sem idempotência vira fonte de duplicidade.
Em sistemas com Kafka, retries, redeliveries e reprocessamentos fazem parte do jogo.
Um comando para liberar estoque pode chegar duas vezes.
Um evento de pagamento autorizado pode ser consumido novamente.
Uma compensação pode ser tentada depois de timeout, enquanto a resposta original ainda está chegando.
Se cada etapa não for idempotente, a saga pode transformar uma falha simples em dano duplicado.
Por isso, cada operação relevante precisa aceitar a pergunta:
"se isso chegar de novo, o que acontece?"
Reservar estoque duas vezes é erro.
Liberar uma reserva já liberada talvez seja sucesso idempotente.
Estornar um pagamento já estornado não deveria gerar novo estorno.
Confirmar um pedido já cancelado precisa ser rejeitado com regra clara.
Essas decisões não pertencem ao Kafka.
Pertencem ao domínio.
Kafka pode entregar novamente.
O consumidor precisa saber reconhecer o que já foi aplicado.
Nem toda falha deve ser compensada imediatamente
Outro erro é tratar qualquer falha como gatilho automático de compensação.
Falhas têm naturezas diferentes.
Uma indisponibilidade temporária no serviço de entrega talvez peça retry.
Uma recusa definitiva do pagamento talvez peça compensação.
Uma resposta desconhecida do gateway talvez peça investigação antes de estornar ou tentar de novo.
Um timeout pode significar falha, atraso ou resposta perdida.
Se o sistema compensa cedo demais, pode desfazer um processo que ainda poderia terminar corretamente.
Se insiste demais, pode prender recursos e atrasar o cliente.
Por isso uma saga precisa de política:
- quando tentar novamente;
- quando parar;
- quando compensar;
- quando pedir intervenção humana;
- quando reconciliar com sistemas externos;
- quando avisar o usuário.
Sem essa política, "saga" vira apenas uma sequência de eventos com esperança.
E esperança não é mecanismo de consistência.
Reconciliação também faz parte do desenho
Mesmo com eventos, retries, idempotência e compensação, alguns casos ficam incertos.
O serviço caiu depois de chamar o gateway, mas antes de gravar o resultado.
O evento foi publicado, mas o consumidor falhou no meio da operação.
O provedor externo retornou timeout, mas processou a solicitação.
Uma compensação foi enviada, mas a confirmação nunca chegou.
Nesses cenários, o sistema precisa reconciliar.
Reconciliação é comparar o estado que você acredita ter com o estado real de outro sistema ou de outra fonte confiável.
Pode ser um job.
Pode ser uma consulta ao gateway.
Pode ser uma tela operacional.
Pode ser um processo de reparo baseado em eventos.
O importante é reconhecer que nem todo caso será resolvido no mesmo fluxo feliz da saga.
Sistemas distribuídos precisam de caminho para incerteza.
Sem reconciliação, alguns processos ficam presos em estados intermediários que ninguém entende e ninguém corrige.
Uma regra prática
Quando alguém pedir rollback distribuído, traduza a conversa.
Pergunte:
- quais etapas já confirmaram estado local?
- quais efeitos saíram para sistemas externos?
- quais ações compensatórias existem de verdade?
- quais compensações podem falhar?
- quais operações precisam ser idempotentes?
- qual estado representa "compensando"?
- quando fazemos retry e quando paramos?
- como reconciliamos casos incertos?
- quem enxerga o estado completo do processo?
Essas perguntas tiram a discussão do mundo mágico do rollback global e trazem para o desenho real da saga.
O objetivo não é desistir de consistência.
O objetivo é escolher um modelo de consistência que existe.
O ponto que vale fixar
Saga não é rollback distribuído.
Saga é coordenação de transações locais com compensações explícitas.
Kafka pode ajudar muito nesse desenho porque distribui eventos, preserva histórico e permite reprocessamento.
Mas Kafka não apaga efeitos já confirmados.
Depois que uma etapa aconteceu, o sistema precisa decidir o que fazer a partir dali.
Às vezes a resposta é retry.
Às vezes é compensação.
Às vezes é reconciliação.
Às vezes é intervenção humana.
O erro é vender tudo isso como "rollback".
Rollback sugere que o passado some.
Em sistemas distribuídos, o passado não some.
Ele vira estado, evento, auditoria e responsabilidade de desenho.